
最近、お笑い芸人の「かまいたち」がCM起用された馴染みある大手消費者金融のアコムは、初めての人でも利用しやすい消費者金融で、今までカードローンを使ったことが無い方におすすめです。
ですがもちろん誰でもお金が借りられる事はなく、アコムで借りるには事前審査があります。人によってはアコムの審査に通るかどうか不安に感じる場合もあるでしょう。
「アコムの審査では何が見られる?」
「アコムの審査難易度や審査の流れは?」
「アコムの審査に通るには?審査落ちしたらどうすればいい?」
上記のような疑問を持っている方に向けて、アコムの審査の難易度や流れ・通るためのコツまで解説します。
| 融資額 | 1万円~800万円 |
|---|---|
| 貸付利率 | 実質年率3.0%~18.0% |
| 利用可能な年齢 | 20歳~69歳 |
| 審査時間 | 最短30分 |
| 担保・保証人 | 不要 |
アコムの審査難易度は甘いのか他社カードローンと比較検証してみた
アコムの審査を受ける上で、審査が甘いのか厳しいのか難易度が気になる形が多いのではないでしょうか。
アコムの新規成約率を見ると、申し込んで審査に通過できるのは、申込者のうち40%程度となっています。
アコムの審査の難易度について、他社のカードローンと比較ながら検証しましょう。
アコムの審査通過率は44.5%と他社と比較して高めの設定
アコムの審査通過率はどれくらいか、アコム公式サイトで発表されている直近4ヶ月分の数字を見てみましょう。
| 2020年10月 | 43.1% |
|---|---|
| 2020年11月 | 44.5% |
| 2020年12月 | 42.3% |
| 2021年1月 | 39.6% |
審査通過率とは審査に申し込んだ方のうち、どれくらいの割合の方が審査に通っているかを示した数字です。
月によって変動はありますが、平均43%前後で推移しているケースが多いとわかります。最も高い月でも44.5%の結果。
10人申し込みをしたら、4人程度の方が通るイメージですね。
他者カードローンと比較した場合のアコムの審査難易度について、新規成約率を元に他社カードローンと比較してみましょう。
| 消費者金融 | アコム | アイフル | プロミス | レイク |
|---|---|---|---|---|
| 2020年10月 | 43.1% | 41.5% | 38.7% | 32.2% |
| 2020年11月 | 44.5% | 41.7% | 37.8% | 32.8% |
| 2020年12月 | 42.3% | 39.2% | 35.7% | 34.3% |
参考:アイフル│月次データ
参考:SMBCコンシューマーファイナンス│月次データ
参考:新生銀行グループ│決算・ビジネスハイライト
他の大手消費者金融と比較すると、いずれの月もアコムの審査通過率が最も高くなっています。
大手消費者金融のカードローンの中では、比較的成約しやすいと言えますね。
アコムは銀行カードローンよりは審査難易度が低い傾向
アコムのカードローンは、銀行カードローンよりは審査難易度が低い傾向にあります。
アコムと銀行の審査の特徴を比較しましょう。
| アコム | 金利が高い分幅広い方に融資を行う |
|---|---|
| 銀行 | 金利が低い分審査が厳しくなりがち 普段から取引があるなど信頼できる人に融資をする傾向 |
アコムの上限金利は年18.0%で、銀行カードローンの金利は平均すると年14.5%程度です。
金利が高いカードローンはそれだけ利益が上げられるので、万が一貸したお金が返ってこなくても経営へのダメージが少なくて済みます。
金利が低いと返ってこなかったときのダメージが大きい分、審査が厳しくなりがちです。
銀行カードローンを利用する場合、条件としてその銀行の口座を持っている(申し込みと同時に開設する)よう求められるケースも。
普段から取引があるなど、信頼できる方が審査に通りやすい傾向が見られます。
アコムの審査の流れをイメージしておこう!申し込み方法や提出書類を解説
アコムの審査の流れや申し込みに必要な書類などを詳しく解説していきます。
- 「3秒診断」で審査に通る可能性があるかチェック
- 申し込みをして必要書類を提出する
- 審査が行われる(申し込み内容の確認や在籍確認)
事前に確認してイメージしておくと、申し込みの際に便利ですね。
3つの段階の詳細を確認しましょう。
アコムの審査に通るか3秒診断で簡易的に確認する
アコムでは「3秒診断」を利用すると、申し込んだ際に審査に通る可能性があるかを簡易的にチェックできます。
入力する項目は以下の3つ。
- 年齢
- 年収
- カードローン他社借入額
年齢35歳、年収50万円、カードローン他社借入額0円で試したところ、以下のように結果が表示されました。
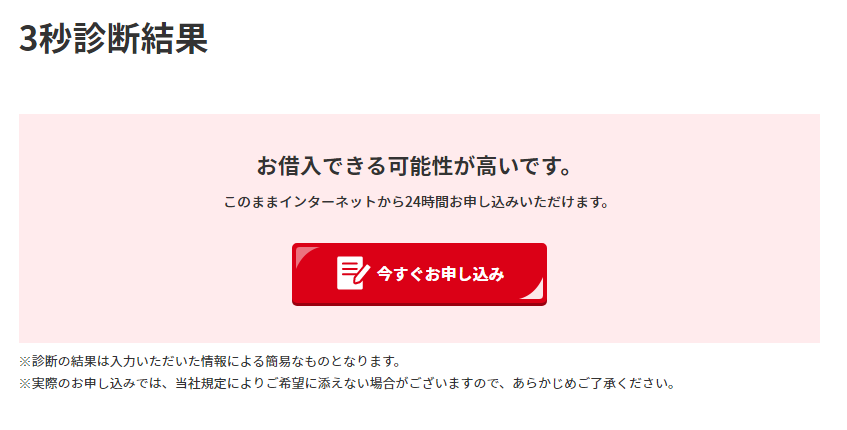
同じ条件でカードローン他社借入額の部分を20万円と入力したところ、次のような表示になりました。
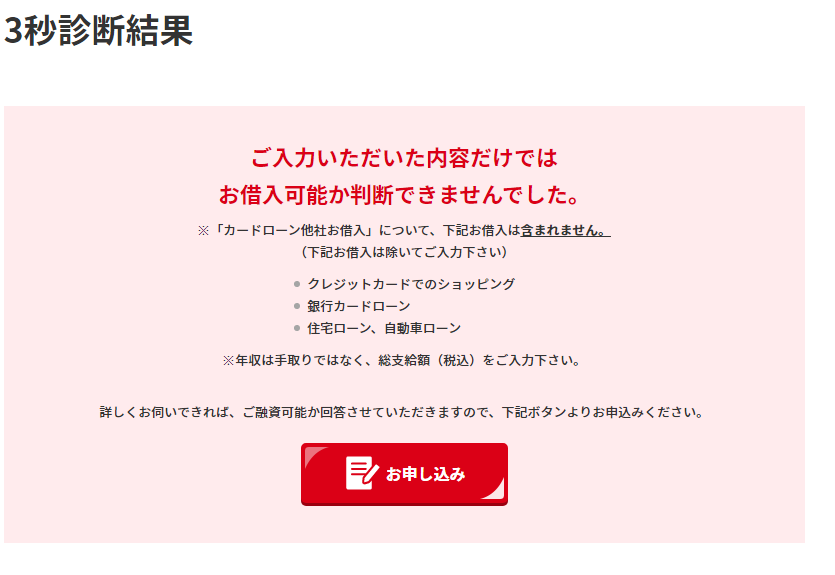
何らかの問題があって、審査に通るのは難しいと考えられますね。今回のケースでは、年収の3分の1を超える借入がある点が問題視されていると予想できます。
3秒診断は3つの項目だけで判断する、簡易的な診断です。
実際に申し込む際には申し込みフォームに入力した詳細の情報を元に審査が行われるので、3秒診断と審査結果が異なる場合もある点に注意しましょう。
アコムの5つの申し込み方法と用意するべき必要書類
アコムでは以下の5つの方法で申し込めます。
| 申し込み方法 | 特徴 |
|---|---|
| インターネット | 24時間申し込み可能(審査可能時間は限りあり) 来店不要で契約できる 即日振込での借入にも対応可能 誰にも会わず契約可能 |
| 店頭窓口 | その場で契約まで可能 営業時間が平日9:30~18:00なので時間が取りにくい場合も 人に見られる可能性がある |
| 自動契約機 | その場で契約まで可能 営業時間は9:00~21:00 土日祝日でも申し込める 人に見られる可能性がある |
| 電話 | 24時間申し込み可能(18時以降に電話すると回答は翌日) 来店不要で契約できる 誰とも会わずに契約可能 オペレーターとのやり取りに時間がかかるケースも |
| 郵送 | 書類を取り寄せる必要がある 郵送でやり取りするので借入までに時間がかかる |
店頭窓口や自動契約機は、一部店舗で営業時間が異なる場合があります。
インターネットが使える環境がある方は、インターネットからの申し込みがおすすめです。
申し込みが済んだら必要書類を提出します。
インターネットで申し込む場合は、申し込み後に届くメールに記載されているURLからログインして書類の提出方法を確認しましょう。
書類は以下のいずれかの方法で提出できます。
- 会員ログインからアップロード
- アプリからアップロード
- FAX
- 店頭窓口で提出
- 自動契約機で提出
- 郵送
運転免許証やマイナンバーカードなどの本人確認書類が必須
必要書類は以下の2点です。
- 本人確認書類
- 収入証明書類(必要に応じて)
アコムの場合、以下の書類が本人確認書類として利用できます。
- 運転免許証
- 健康保険証
- パスポート
- マイナンバーカード
本人確認書類は、有効期限内のものを用意しましょう。健康保険証を提出する方は、記号・番号・保険者番号・QRコードが写らないよう、塗りつぶすなどの対応が必要です。
本人確認書類の提出方法によって、必要とされる書類が以下のように異なります。
| スマホアプリから提出 | 上記の書類をいずれか1点 |
|---|---|
| Web・FAX・郵送で提出 | 上記の書類をいずれか2点 1点しかない場合は発行から6ヶ月以内の補足書類※を追加で提出 |
| 店頭窓口・自動契約機で提出 | 上記の書類をいずれか1点 健康保険証を利用する場合は補足書類を提出または契約後にアコムからの郵便物を受け取る |
※補足書類は住民票の写し・公共料金の領収書
書類の提出方法に合わせて、必要な書類を用意しましょう。
借入額が50万円を超えるなら収入証明書類も必要
アコムでの借入額が50万円を超える場合は、法律の取り決めによって収入証明書類も必要です。
すでにアコム以外から借入をしているは、現在の借入額と新たにアコムで借入をしたい金額と合わせて100万円を超える場合に、収入証明書類の提出が求められます。
個人が借入れをしようとする場合において、①ある貸金業者から50万円を超えて借入れる場合、こ他の貸金業者から借入れている分も合わせて合計100万円を超えて借入れる場合、のどちらかに当てはまると、「収入を証明する書類」の提出が必要です。(引用元:日本貸金業協会│「収入を証明する書類」の提出が必要な場合があります)
例えば以下のような場合に、収入証明書類の提出が必要です。

法律上必要ではなくても、審査担当者が必要と判断すれば提出が求められるケースも。
アコムで収入証明書類として利用できるのは、以下の書類です。
- 源泉徴収票
- 給与明細書(直近2ヶ月分+あれば直近1年分の賞与明細書も提出)
- 市民税・県民税額決定通知書
- 所得証明書
- 確定申告書・青色申告書・収支内訳書
アコムの審査担当者が申し込み内容と信用情報を確認する
必要書類がそろったら、審査担当者が申込内容と信用情報を確認します。
本当に本人が申し込んでいるか、返済能力はありそうかなど、申し込みの際に入力した項目と必要書類を元に確認します。
詳しくは後述しますが、信用情報の確認も同時に行われます。
申し込みの際に入力を求められるのは、以下の項目です。それぞれの項目が審査にどう影響するのか、確認しましょう。
| 情報の種類 | 項目 |
|---|---|
| 申込者の情報 | 氏名・旧姓・生年月日・性別・独身か既婚か・メールアドレス |
| 自宅情報 | 住所・電話番号・住居種類(持ち家か借家かなどの分類)・入居年月・家賃や住宅ローンの負担 |
| 家族情報 | 世帯主かどうか、同一生計人数 |
| 勤め先情報 | 勤務形態を選択・勤務先の電話番号を入力 ※自動的に企業データベースを検索 |
| 他社借入状況について | 他社借入総額 |
| 希望極度額 | 1万円~800万円の範囲で希望額を入力 |
各項目で見られる内容の詳細をチェックしましょう。
申込者の情報は、本人確認に利用されています。誰が借入するのか、他人の名前を使っていないかなどを確認する項目です。
自宅情報と家族情報では、以下の点をチェックしています。
- 住居種類と入居年月で連絡のつきやすさ
- 家賃や住宅ローンの負担で返済能力
- 家族構成で返済能力
例えば持ち家で居住年数が長い方は、今後引っ越す可能性が低いと考えられます。返済が滞った時に連絡がつかなくなると困るので、簡単に引っ越せない状態の方が有利という判断に。
家賃や住宅ローンの負担や家族構成は、返済に回せる余裕がどれくらいありそうかを判断する項目です。
住所が不定などの理由がなければ、自宅情報は審査に通るかどうかよりも利用限度額を決める参考にされるケースが多くなっています。
審査結果に大きく影響するのは、勤め先情報・他社借入状況・希望限度額です。
安定収入がある方しかアコムで借入はできないので、勤めていることが確認できなければ審査には通りません。
アコムの申し込みフォームは、勤務形態を選択して勤務先の電話番号を入力すると、自動的に企業データベースが検索されるシステムです。
他社借入については、信用情報が確認されます。信用情報とはクレジットカードの利用状況やローンの返済状況などの情報で、信用情報機関と呼ばれる機関が情報を集めて管理する仕組みです。
信用情報を照会すると、誰がどのようなローンを利用していて、返済状況はどうかなどがすべてわかります。
信用情報を確認した結果、以下の場合は審査に通りません。
- アコム以外の貸金業者ですでに年収の3分の1の借入をしている
- 滞納しているローンがある
- 債務整理をした
年収の3分の1の借入をしている方は、貸金業法のルールによってそれ以上の借入が認められません。
アコムでは申し込み条件として、返済能力があることも挙げられています。滞納しているローンがある方や債務整理をしてからあまり年数が経っていない方は、返済できる状況にないと判断されるので審査に通りません。
アコムで借りられるのは最大で年収の3分の1までですが、希望限度額が低い方が審査に通る確率は高くなります。
年収が150万円の方が50万円借りた場合と10万円借りた場合では、10万円の方が無理なく返済できますよね。
希望限度額を記入する際は、今本当に必要な金額を記入しましょう。
書類を元に審査を行った後は、在籍確認が行われます。
在籍確認とは本当に申し込みの際に記入した職場で働いているか、電話をして確認を取るものです。
アコムでは申込書の内容を元に審査を行っているので、記入された職場が嘘だと審査をした意味がありません。
安定収入を得ている裏付けを取るために、在籍確認は重要な意味を持っています。
在籍確認の電話を避けるなら電話で相談
私用電話が禁じられている・普段外部から電話がかかってこないなど、在籍確認の電話がかかってくると困る職場もあります。
なかにはプライバシーの保護のために、外部の電話に社員の情報を教えない職場もあり、在籍確認ができないケースも。
在籍確認ができないと審査に通らないので、電話での在籍確認ができない理由がある場合は、アコムに電話をして相談しましょう。
アコムで即日融資を受けるために押さえておくべきコツを紹介
アコムでは状況によって、申し込んだその日のうちにお金を借りる即日融資も可能です。
アコムで即日融資を受けるにはどうすればいいのか、コツを紹介します。
アコムのおすすめの申し込み方法は、インターネットです。
インターネット申し込みのメリットは、以下の通り。
- 家に居ながら申し込める
- 契約方法がネットと来店で選べる
- オペレーターとのやり取りが不要で手軽
インターネットからの申し込みなら、そのままネット上での契約も可能です。
ネット上で契約した場合、以下の点に注意しましょう。
- 即日融資を受けるなら借入は振り込みになる
- 後日カードが郵送される
アコムではインターネットで契約して当日借入をしたい場合、振り込みによる融資になります。
利用したい金融機関が振り込みに対応できる時間内の手続きが必要です。
来店で契約するとカードがその場で受け取れるので郵送物がありませんが、ネット上で契約するとカードが郵送されます。
郵便物を受け取りたくないなら、来店での契約を選びましょう。
アコムの審査は最短30分で回答
アコムの審査時間は最短で30分です。
ネットからなら24時間いつでもお申し込みいただけます。審査結果は最短30分でメールやお電話でご連絡いたします。
ご契約・カード発行も即日可能となりますので、お急ぎの場合にも対応できます。(引用元:アコム│アコムのカードローンのメリット)
最短で30分なので、審査状況や混雑状況によってはもっと時間がかかるケースもあります。
アコムの自動契約機は土日でも即日融資可能
自動契約機に出向ける場合は、自動契約機で申し込みをするとその場でカードの受け取りが可能です。
インターネットで申し込んで自動契約機で契約すると、来店までの時間が短縮できます。
自動契約機の営業時間は9:00~21:00(一部店舗を除く)で、年末年始を除いて年中無休です。
店舗は平日のみの営業で、営業時間は9:30~18:00。土日祝日も利用できて、営業時間も長い自動契約機の方が便利ですね。
最短でも審査に30分、その後契約手続きも行う必要があるので、営業時間終了ギリギリに来店すると即日融資はできません。
即日融資を受けたい場合は、どんなに遅くても営業時間が終了する1時間前の20時までには来店しましょう。
即日融資には遅くても20時までに申し込む
アコムではインターネットからの申し込みでも、即日融資に対応可能です。
インターネットで申し込んだ場合も、審査結果の連絡は最短30分です。
アコムでは契約手続きを、メール送信日の22時までに行う必要があります。
審査可能な時間は明記していませんが、借入まで最短60分かかる点と22時までに契約手続きを完了させる必要がある点から、遅くても20時までには申し込みを済ませましょう。
インターネットでお申し込みいただくと、審査時間は最短30分、お借入まで最短60分で可能です。お申し込みは24時間365日受け付けております。(引用元:アコム│よくあるご質問)
自動契約機でなければ振り込み対応時間を確認しておく
自動契約機で契約をしてカードを受け取ればアコムATMや提携ATMからカードで借入できますが、インターネットで契約をする場合は即日融資を受けるなら融資方法は振り込みになります。
アコムの場合スマホアプリをカード代わりにATMから借入や返済をする「スマホATM」は、返済にのみ対応していて借入には利用できません。
振り込みに対応できる時間内に契約を済ませなければ即日融資が受けられないので、事前に対応時間を確認しましょう。
アコムの場合楽天銀行に口座があれば、メンテナンス時を除いて24時間365日最短1分での振り込みが可能です。
以下の4つの金融機関は、土日祝日でも振り込みに対応しています。
- 三菱UFJ銀行
- ゆうちょ銀行
- みずほ銀行
- 三井住友銀行
振り込み対応時間は以下の通り。
| 曜日 | 振り込み予定時間 |
|---|---|
| 月曜日 | 0:10~8:59に受付→当日9:30頃 9:00~23:49に受付→受付完了から1分程度 |
| 火曜日~金曜日 | 0:10~23:49に受付→受付完了から1分程度 |
| 土日・祝日 | 0:10~8:59に受付→当日9:30頃 9:00~19:59に受付→受付完了から1分程度 20:00~23:49に受付→翌日9:30頃 |
振込実施時間拡大(モアタイム)金融機関に分類される金融機関は、平日なら遅い時間まで振り込みに対応可能です。
| 曜日 | 振り込み予定時間 |
|---|---|
| 月曜日~金曜日 | 0:10~8:59に受付→当日9:30頃 9:00~17:29に受付→受付完了から1分程度 17:30~23:49に受付→翌営業日9:30頃 |
| 土日・祝日 | 0:10~23:49に受付→翌営業日9:30頃 |
上記以外の金融機関「その他の金融機関(コアタイム)」の場合は、振り込み時間が以下のようになります。
| 曜日 | 振り込み予定時間 |
|---|---|
| 月曜日~金曜日 | 0:10~8:59に受付→当日9:30頃 9:00~14:29に受付→受付完了から1分程度 14:30~23:49に受付→翌営業日9:30頃 |
| 土日・祝日 | 0:10~23:49に受付→翌営業日9:30頃 |
申し込んでから電話で連絡するのが即日融資のコツ
アコムで急いで融資を受けたい場合、申し込み後に電話をして早めに審査をしてもらえないか交渉するのが即日融資のコツです。
インターネットから申し込みをすると、申し込み完了のメールが届きます。
メールが届いたら受け付けが終わったとわかるので、アコムに電話をして早めに審査をしてもらえないか相談しましょう。
審査が早く開始されれば、審査結果が出るのも早くなります。
連絡をすれば審査の開始が早まるだけで、審査内容を省略するなどの理由で審査が甘くなるわけではありません。
会社が休みで在籍確認が取れないときの2つの対処法
会社が休みで在籍確認が取れない場合、対応方法は2つ考えられます。
電話で相談する
1つが電話で相談する方法です。
電話で相談すると、在籍確認を後回しにして融資が先に受けられるケースも。ただしその場合は高額の借入は不可能です。
無理なく返済ができると思われる10万円程度なら、先に借りられる可能性があります。
アコムは法律を守って融資をしているので、申込者の年収の3分の1を超える融資ができません。
法律の点から考えても、10万円程度の融資なら年収が30万円あれば問題がありません。年収30万円なら月に2万5千円程度の収入があればいいので、アルバイトでも満たせますね。
収入証明書類を提出する
2つ目が収入証明書類を提出する方法です。
在籍確認は収入がある裏付けを取るものなので、収入があると証明できれば電話以外の方法に替えてもらえるケースも。
担当者に書類の提出に替えられないか、相談しましょう。
申し込み内容や提出書類の不備がないか十分に確認する
申し込む際は申込内容や提出書類に不備がないか、きちんと確かめる必要があります。
急いで申し込むと申し込みフォームの項目の入力ミスが起こりがちです。ミスがあると確認に時間が取られてスムーズに審査が進まないので、最短時間で審査が終わらない原因に。
提出書類に不備があると送り直しや確認に時間がかかります。
急いでいても丁寧に準備をして、確認に時間を取られないようにしましょう。
アコムの審査に通るための条件を確認しよう
アコムの審査に通るために満たしておきたい条件を、チェックしましょう。
- 年齢の条件を満たしているか
- 安定収入はあるか
- 在籍確認が取れるか
- 金融事故を起こした経験がないか
- 半年のうちに3件以上ローンに申し込んでいないか
- 他社借入状況に問題はないか
それぞれについて、詳しく紹介します。
申し込み年齢が20歳から69歳であること
アコムを利用できるのは、20歳から69歳の方です。
貸し付け条件の部分には20歳以上と下の年齢しか記載されていませんが、「3秒診断」のページを見ると年齢の部分に20歳~69歳が対象と記載されています。
貸付対象者
20歳以上の安定した収入と返済能力を有する方で、当社基準を満たす方(引用元:アコム│貸付条件(カードローン))
アコムの審査のポイントは高い年収が求められるわけではない
アコムで借入をするには、安定収入が求められます。
アコムで借入ができるのは、以下の勤務形態の方です。
- 正社員
- パート
- アルバイト
- 契約社員
- 派遣社員
- 自営業者(個人事業主)
- アルバイトをしている学生
成人していて何らかの形で申込者自身が収入を得ていれば、アコムで借入できる可能性があります。
無職の方・自身に収入がない専業主婦(夫)・アルバイトをしていない学生などは、条件を満たしていないので融資の対象となりません。
年金受給者は、アルバイトや自営業などで別の収入があれば借りられます。
アコムの審査のポイントは、どれだけ高い収入を得ているかではなく、少額でも毎月安定した収入を得ているかどうかです。
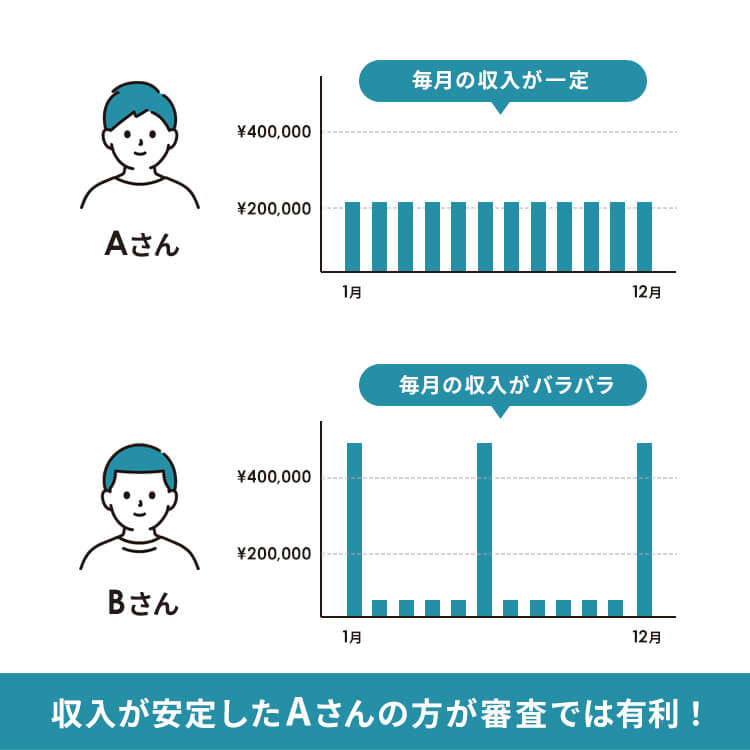
上の画像のAさんは、決して高い月収とは言えませんが毎月同じ金額を安定してもらっています。
対するBさんは年に何度か高い月収をもらっていますが、毎月の収入は規則性が無くバラバラです。
この2人を比較すると、アコムの審査に通る可能性が高いのはAさんの方になります。
アコムで借入をしている方の年収は、以下の通り。
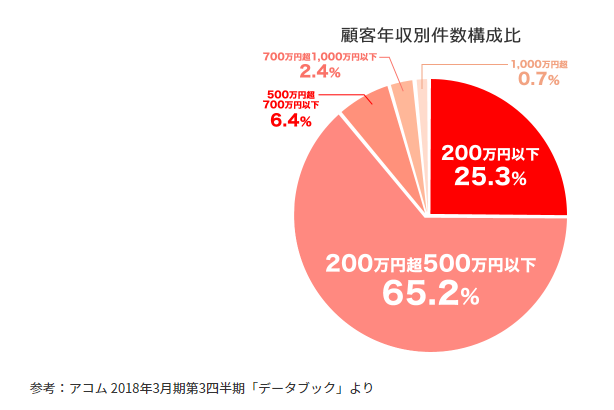
アコムを利用している方の約90%が年収500万円以下で、25%程度の方が年収が200万円以下です。
毎月同じくらいの収入を継続して得ていれば、審査に通る可能性があります。
アコムからの在籍確認を取れる状況にしておくこと
在籍確認は収入の裏付けを取る重要なものなので、在籍確認が取れる状況にしておく必要があります。
職場に電話をかけていい場合は、以下のような対応になるので難しく考えなくて大丈夫です。
| 本人が電話に出られる場合 | 簡単な確認で終了 |
|---|---|
| 本人が電話に出られない場合 | 電話に出た人が「会議中」「外出中」などと答えてくれれば終了 勤め先に申込者がいるとわかれば在籍確認が取れる |
電話は担当者の個人名でかけるので、アコムの名前は出ません。電話に関しても、最大限プライバシーに配慮してかけてくれます。
お客さまのプライバシーに十分配慮し、担当者の個人名で連絡いたします。
【自宅・勤務先へのご連絡例】○○(担当者の個人名)と申しますが、●●さん(お客さま)いますか?
個別事情などにより、ご心配な点やご不安な点がございましたら、下記のフリーコールへご相談ください。(引用元:アコム│よくあるご質問)
問題なのは職場が休みの日に申し込んだ場合や、電話ができない事情のある職場に勤めている場合です。
事情がある場合はアコムのフリーコールに連絡をして、収入証明書類の提出など電話以外の方法で在籍確認をしてもらえるか確認しましょう。
過去に金融事故を起こしていないこと
過去に金融事故(延滞や債務整理など返済上の問題)を起こしている場合は、信用情報機関に情報が登録されている期間を過ぎるまで審査には通らないと考えましょう。
国内には3つの信用情報機関があります。
- CIC(株式会社シー・アイ・シー)※
- JICC(株式会社日本信用情報機構)※
- 全国銀行個人信用情報センター
※貸金業法に関連して内閣総理大臣によって指定されている指定信用情報機関
信用情報機関は加盟している業者から利用者の情報を集めて管理し、申し込みを受けた業者から情報の照会があれば集めている情報を提供します。
アコムはCICとJICCの両方に加盟しています。業者によっては、どちらか1社にしか加盟していない場合もあります。
アコムは両方に加盟しているので、1社にしか加盟していない業者の利用者の情報も確認可能です。
全国銀行個人信用情報センターの会員は主に銀行や信用金庫などの金融機関で、指定信用情報機関と金融事故に関する情報を共有しています。
貸金業者での金融事故だけではなく銀行などのローンもアコムの審査に関係するので、注意しましょう。
金融事故に関する情報が掲載される期間は、信用情報機関によって以下のように違います。
| 信用情報機関 | CIC | JICC | 全国銀行個人信用情報センター |
|---|---|---|---|
| 延滞 | 契約継続中および契約終了後5年間 | 契約継続中および契約終了後5年以内 | 契約期間中および契約終了後5年を超えない期間 |
| 債務整理 | 債務整理の記録が直接掲載されるわけではない 長期延滞の記録か代位弁済の記録は5年以内の期間登録される ※自己破産は5年を超えない期間 |
5年を超えない期間 | 5年を超えない期間 ※個人再生・自己破産は10年を超えない期間 |
延滞や債務整理の経験があると、少なくとも5年間は情報が残ります。
情報が消えてからであれば、再度の申し込みで審査に通る可能性もあります。
年収の3分の1に近い借入がないこと
貸金業者では、貸金業法によって年収の3分の1を超える融資は認められていません。
すでに年収の3分の1に近い借入がある場合にアコムで新たな契約をすると、法律の範囲を超える可能性があるため、アコムの審査には通りません。
他社での返済を進めてからアコムの審査を受ける方が、通る可能性が高まります。
過去半年以内に3件以上ローンなどに申し込んでいないこと
過去半年以内に3件以上ローンなどに申し込んでいると、次々にお金を借りるタイプなのでいずれ返済が滞ると思われて、審査で不利になります。
期間が過去半年以内なのは、ローンに申し込みをした記録が信用情報機関に半年間残るからです。
次々にローンに申し込んだ場合は、最後の申し込みから半年開けて再度申し込みましょう。
他社の借入があるなら借入件数と残高を減らしておく
他者から借入がある方は、借入件数と残高を減らしておくと審査に通る可能性が高まります。
借入件数が多い場合、あちこちで借入をするタイプとみなされて返済能力が不安視されます。
借入残高が多いと、法律の関係で年収の3分の1を超える可能性があるので、審査に通りません。
借入額が少ない借入先で完済して解約するなど、借入件数と残高を減らすと効果的です。
アコムの審査におちたら考えるべき対策
アコムの審査に落ちても、すぐに諦める必要はありません。他社カードローンに申し込むなどの対応方法があります。
アコムの審査に落ちたらどうすればいいか、考えられる対策を紹介します。
他社カードローンの利用も検討する
アコムの審査に落ちた場合、他社カードローンに申し込み直す方法があります。
カードローンによって審査基準は違うので、同じ方が申し込んでもA社では通ってB社では落ちるケースがあるからです。
新たに申し込む場合は、1社ずつ順番に申し込みましょう。
一度に複数の業者に申し込むと、お金に困って何とか借入をしようとしていると思われ、返済能力がないのではと思われる可能性があります。
6ヶ月後にもう一度申し込みをする
借入を急いでおらず待てるようなら、今回の申し込みから6ヶ月後にもう一度アコムに申し込む方法もあります。
信用情報機関に申し込みの情報が残るのは6ヶ月間なので、その期間を過ぎるまで待つ必要があるのです。
もう一度申し込む際には、前回の審査で何が問題だったか考えて、改善できる部分は改善しておきましょう。例えば以下のような可能性がありますね。
| 申込書に不備があった | 正確に情報を記入するよう気を付ける |
|---|---|
| 在籍確認ができなかった | 事前にアコムに相談する |
| 年収の3分の1近い借入があった | 借入額を減らす |
| 借入件数が多かった | 完済できそうなところを完済する |
| 金融事故を起こしている | 信用情報機関から情報が消えるのを待つ |
金利の低い銀行カードローンも検討する
消費者金融のカードローンではなく、銀行カードローンに申し込む方法もあります。
メリットは3つ。
- 審査基準が違うのでアコムで落ちても通る可能性がある
- アコムより低金利で借りられる商品もある
- 普段取引があると金利優遇がある場合も
カードローンの審査基準は商品ごとに違うので、アコム以外で審査を受け直せば通る可能性も。
銀行カードローンの金利は商品によって様々ですが、アコムの上限年18.0%よりも上限の金利が低く設定されている商品も多くあります。
一例を見てみましょう。
| 銀行カードローン | 上限の金利 |
|---|---|
| みずほ銀行カードローン | 年14.0% |
| イオン銀行カードローン | 年13.8% |
| 三井住友銀行カードローン | 年14.5% |
| 三菱UFJ銀行「バンクイック」 | 年14.6% |
| ジャパンネット銀行ネットキャッシング(通称:カードローン) | 年18.0% |
ジャパンネット銀行はアコムと同じ年18.0%ですが、その他の銀行のカードローンはいずれもアコムより金利が低く設定されています。
10万円借入をして1年で返済した場合、アコムの利息は10,016円です。最も金利が低いイオン銀行カードローンの場合、7,628円です。
参考:E-LOAN │カードローンのかんたん返済額シミュレーション
普段取引がある銀行のカードローンを利用すると、金利の引き下げが受けられるケースも。
例えば以下のような優遇があります。
| 銀行・商品名 | 金利引き下げの例 |
|---|---|
| みずほ銀行カードローン | 住宅ローン利用者は年0.5% |
| 七十七銀行「77カードローン」 | Web契約で年3.1% 消費者ローン・住宅金融支援機構利用で年0.7% 給与振込・年金受け取りで年0.7% 総合口座(定期預金10万円以上) で年 0.5% 積立預金・財形預金の利用で年 0.5% 77カード(クレジットカード)の契約で年 0.4% 5大公共料金・学費自動振替が2項目以上あれば年 0.3% 住宅ローン利用者は年11.0%の金利が年4.8%に(住宅ローン利用期間中、店頭での契約に限る) |
取引の内容に応じて金利の引き下げが受けられる銀行を利用すれば、よりお得に借りられる場合もあります。
銀行のカードローンには保証会社がついていますが、アコムが保証会社になっているカードローンは避けましょう。
保証会社とは次の2つの役割を持つ会社です。
- 審査を行う
- 返済が滞った場合に利用者の代わりに返済をする
保証会社は銀行のカードローンの申し込みがあった際に、保証してもいいか判断するための審査を行います。保証会社の審査に通った方は返済能力があると考えられるので、銀行も安心して融資が可能です。
保証会社の審査とは別に銀行も独自の審査を行いますが、銀行は保証会社の審査の結果を受けて申込情報に間違いがないかなどの視点から審査をしています。
万が一返済が滞っても保証会社が利用者に代わって返済をするので、銀行はお金が返ってこないリスクも避けられる仕組みです。
利用している保証会社は、以下の例のように銀行によって違います。
| 銀行カードローン | 保証会社 |
|---|---|
| みずほ銀行カードローン | 株式会社オリエントコーポレーション(オリコ) |
| イオン銀行カードローン | イオンクレジットサービス(株) またはオリックス・クレジット(株) |
| 三井住友銀行カードローン | SMBCコンシューマーファイナンス株式会社 |
| 三菱UFJ銀行カードローン「バンクイック」 | アコム株式会社 |
| ジャパンネット銀行ネットキャッシング(通称:カードローン) | SMBCコンシューマーファイナンス株式会社 |
上記の銀行カードローンでは、三菱UFJ銀行カードローン「バンクイック」がアコムを保証会社としています。
保証人
不要
※保証会社(アコム㈱)の保証をご利用いただきますので、保証人は必要ありません。 (引用元:三菱UFJ銀行のカードローン バンクイック│商品説明書)
保証会社は自社で小口の融資を行う際のノウハウを元に、保証会社としての審査を行っています。
そのため保証会社として審査をした場合も、審査結果が同じになるケースが一般的です。
家計を見直して支出を抑える
お金が借りられない場合は、支出を抑える対策も有効です。
日本貸金業協会によると、希望通りに借入ができなかった方が最も多く取るのは支出を抑える方法です。
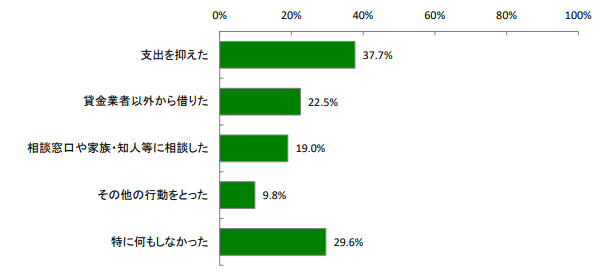
支出を抑えられれば、お金を借りずに乗り切れる場合もあります。
家計を見直す際に有効な方法の例は、以下の通り。
- 外食を減らすなど食費の見直し
- 娯楽費や交際費を抑える
- 格安スマホに変えるなど通信費の見直し
- 保険の見直し
できそうな対策から始めるといいですね。
審査が不安なら中小消費者金融も検討する
審査が不安な場合は、中小消費者金融からの借入も検討しましょう。
大手消費者金融と中小消費者金融の審査方法には、以下のような違いがあります。
| 大手消費者金融 | 中小消費者金融 |
|---|---|
| スコアリングシステム(自動与信審査システム)を採用 機械的に審査を行う |
スコアリングシステムを採用している場合もある 人の手で審査を行っている業者もある |
大手ではスコアリングシステム(自動与信審査システム)によって、人の手を通さず機械的な判断を行いスピーディーな融資を可能としています。
機械的な審査なので、業者間の差はそこまで大きくありません。
中小消費者金融にはスコアリングシステムを採用している業者と、人の手で審査を行っている業者があります。
中小消費金融が大手と同じ切り口で審査を行っていると、便利な大手に顧客が流れます。
人の手で審査をする場合、差別化を図るために大手とは違った独自の切り口で審査を行っているケースが多いので、大手の審査結果と異なる結果が出る可能性も。
ただし審査を行わずに融資をする業者はありません。視点が違うだけで、中小消費者金融もきちんと審査を行ったうえで融資をしています。

